
Conjoint R
|
|
Ten artykuł należy dopracować |
Logo programu | |
| Autor | Andrzej Bąk, Tomasz Bartłomowicz |
|---|---|
| Pierwsze wydanie | 2 października 2011; ponad 12 lat temu |
| Aktualna wersja stabilna | 1.41 / 26 lipca 2018; ponad 5 lat temu |
| Język programowania | R (język programowania) |
| Platforma sprzętowa | i386, x64 |
| System operacyjny | Windows, Linux/Unix, Mac OS |
| Rodzaj | Conjoint Analysis, Oprogramowanie statystyczne |
| Licencja | GNU GPL |
| Strona internetowa | |
conjoint R[1] – pakiet oprogramowania statystycznego dla programu GNU R. Zawiera implementację tradycyjnej metody conjoint analysis. Jest napisany w języku programowania R jako rozwinięcie (moduł) popularnego oprogramowania statystycznego w postaci programu GNU R, współpracuje także z programami dedykowanymi dla środowiska R takimi jak: RStudio oraz Microsoft R Application Network.
Pakiet conjoint obejmuje zbiór funkcji[2], które umożliwiają analizę preferencji wyrażonych na podstawie danych empirycznych reprezentujących oceny konsumentów profilów produktów lub usług (tzw. użyteczności całkowite, użyteczności empiryczne). Użyteczności całkowite są przedmiotem dekompozycji na tzw. użyteczności cząstkowe, które w dalszej analizie wykorzystywane są do określenia ważności produktu lub usługi, zdefiniowania produktu o optymalnych cechach, wyodrębnienia segmentów nabywców o zbliżonych preferencjach, itp[3]. Dekompozycja jest przeprowadzana na podstawie modelu regresji wielorakiej ze zmiennymi sztucznymi (funkcja lm z pakietu stats [R Core Team 2018[4]]). W szczególności, pakiet conjoint programu GNU R umożliwia:
- estymację parametrów modelu conjoint analysis (użyteczności cząstkowych) w przekroju respondentów (modele indywidualne) i całej próby (model zagregowany),
- estymację ważności atrybutów (cech opisujących profile produktów lub usług),
- estymację teoretycznych użyteczności całkowitych profilów produktów lub usług,
- szacowanie udziału w rynku profilów symulacyjnych,
- segmentację respondentów.
W pakiecie dostępne są również funkcje generujące pełny i cząstkowy (w tym ortogonalny i efektywny) układ czynnikowy niezbędny do przygotowania odpowiedniego kwestionariusza ankietowego, który jest narzędziem gromadzenia danych o preferencjach wyrażonych respondentów z wykorzystaniem metody conjoint analysis.
Kod źródłowy pakietu conjoint opublikowany jest na zasadach licencji GNU GPL. Dostępne są wersje binarne dla systemów Windows, Macintosh oraz systemów uniksowych (w tym systemu Linux, który jest naturalnym środowiskiem projektu GNU R).

Wymagania[edytuj | edytuj kod]
Poprawne działanie pakietu conjoint wymaga zainstalowania wersji bazowej programu GNU R oraz dodatkowych pakietów (m.in. AlgDesign [Wheeler 2015[5]] i innych), które począwszy od wersji 3.3.2 programu GNU R są pobierane i instalowane automatycznie wraz z pakietem conjoint. Pakiet można pobrać oraz zainstalować ze strony internetowej repozytorium CRAN R (CRAN.R-project.org[1]) oraz strony WWW Katedry Ekonometrii i Informatyki Uniwersytetu Ekonomicznego we Wrocławiu (keii.ue.wroc.pl). Łączna liczba instalacji pakietu conjoint (stan na 21 czerwca 2018) przez użytkowników programu RStudio przekroczyła 35000 pobrań (statystyka nie uwzględnia użytkowników korzystających z innych wersji programów dla R, w tym przede wszystkim oryginalnej wersji środowiska R). Miesięczną liczbę pobrań pakietu conjoint oszacowaną z wykorzystaniem pakietu dlstats [Yu 2017[6]] oraz zaprezentowaną na wykresie za pomocą pakietu ggplot2 [Wickham i in. 2018[7]] (odpowiedni kod R poniżej) przedstawia rys. 1.
library("ggplot2")
library("dlstats")
x<-cran_stats("conjoint")
ggplot(x,aes(end,downloads,group=package,color=package))+geom_line() +
geom_point(aes(shape=package))+scale_x_date(date_breaks="1 year",date_labels="%Y")
Historia i wersje[edytuj | edytuj kod]
Pierwsza wersja pakietu conjoint na serwerze CRAN pojawiła się 2 października 2011 roku. Pakiet może być zainstalowany na komputerze z procesorem 32-bitowym lub 64-bitowym. Funkcjonalność pakietu jest taka sama w obu przypadkach, z wyłączeniem cząstkowych układów czynnikowych. W systemach 32-bitowych istnieje możliwość otrzymania innego cząstkowego układ czynnikowego niż w przypadku systemów 64-bitowych (wynika to z uwarunkowań numerycznych dotyczących długości słowa maszynowego i jego wpływu na ziarno generatora liczb pseudolosowych, które jest wykorzystywane w procedurze generowania układów cząstkowych). Zaprezentowane w artykule przykłady zostały opracowane z wykorzystaniem procesorów 64-bitowych pracujących pod kontrolą systemu operacyjnego Windows 10.
Funkcje pakietu[edytuj | edytuj kod]
W wersji bieżącej pakietu conjoint (1.41) oferowanych jest 16 funkcji, które umożliwiają: estymację parametrów modelu conjoint analysis oraz segmentację respondentów (funkcje: caModel, caSegmentation), estymację teoretycznych użyteczności cząstkowych i użyteczności całkowitych w przekroju respondentów (funkcje: caPartUtilities, caTotalUtilities), szacowanie ważności atrybutów oraz użyteczności cząstkowych poziomów atrybutów na poziomie zagregowanym (funkcje: caImportance, caUtilities), a także – w ramach analizy symulacyjnej – szacowanie udziału w rynku profilów symulacyjnych (funkcje: caBTL, caLogit, caMaxUtility). Do funkcji specjalnego przeznaczenia zaliczyć należy funkcję konwertującą zbiór danych o preferencjach empirycznych (funkcja caRankToScore) oraz funkcje umożliwiające uzyskanie zbiorczych wyników wybranych pomiarów oraz symulacji (funkcje: Conjoint, ShowAllSimulations oraz ShowAllUtilities). Ponadto, w pakiecie dostępne są narzędzia wspomagające projektowanie badania ankietowego tj. konstrukcję odpowiednich układów czynnikowych, w szczególności umożliwiające redukcję pełnego zbioru profilów do postaci układów cząstkowych (ortogonalnych i efektywnych). Pakiet conjoint wykorzystuje w tym celu funkcje pakietu AlgDesign [Wheeler 2015[5]] programu GNU R. Zastosowanie funkcji pakietu AlgDesign w pakiecie conjoint realizowane jest w postaci funkcji, które umożliwiają generowanie ortogonalnych i efektywnych cząstkowych układów czynnikowych oraz ich kodowanie za pomocą zmiennych sztucznych (funkcje: caFactorialDesign, caEncodedDesign oraz caRecreatedDesign). Do wygenerowania odpowiedniego układu czynnikowego (pełnego i cząstkowego) wystarczające są dane dotyczące liczby branych pod uwagę atrybutów (zmiennych, cech, czynników) oraz ich poziomów (realizacji, wartości, obserwacji) oraz nazw atrybutów i poziomów. Szczegółowa charakterystyka wszystkich dostępnych funkcji dostępna jest w oficjalnej dokumentacji[8] pakietu conjoint programu R oraz na innych nieoficjalnych stronach internetowych[9],[10],[11],[12] prezentujących zastosowanie pakietu. W tabeli zestawiono zwięzły opis przeznaczenia funkcji pakietu conjoint.
| Generowanie układów czynnikowych oraz konwersja danych | |
|---|---|
| caFactorialDesign(data, type="null", cards=NA, seed=123) – funkcja wyznacza (pełny lub cząstkowy) układ czynnikowy z zachowaniem nazw zmiennych oraz ich poziomów | |
| caEncodedDesign(design) – funkcja koduje układ czynnikowy uzyskany za pomocą funkcji caFactorialDesign na potrzeby działania modułu conjoint | |
| caRecreatedDesign(attr.names, lev.numbers, z, prof.numbers) – funkcja odtwarza cząstkowy układ czynnikowy na podstawie numerów profilów z pełnego układu czynnikowego | |
| caRankToScore(y.rank) – funkcja przekształca dane o preferencjach empirycznych mierzonych na skali rang w zbiór danych w postaci ocen punktowych (na skali pozycyjnej) | |
| Szacowanie indywidualnych użyteczności cząstkowych oraz teoretycznych użyteczności całkowitych (w przekroju respondentów) | |
| caPartUtilities(y, x, z) – funkcja oblicza macierz użyteczności cząstkowych poziomów atrybutów w przekroju respondentów (wraz z wyrazem wolnym) | |
| caTotalUtilities(y, x) – funkcja oblicza macierz teoretycznych użyteczności całkowitych profilów w przekroju respondentów | |
| Szacowanie użyteczności cząstkowych poziomów atrybutów (na poziomie zagregowanym) oraz pomiar ważności atrybutów | |
| caUtilities(y, x, z) – funkcja oblicza użyteczności cząstkowe poziomów atrybutów na poziomie zagregowanym | |
| caImportance(y, x) – funkcja oblicza przeciętną relatywną „ważność” wszystkich atrybutów (w ujęciu procentowym) na poziomie zagregowanym | |
| Analiza symulacyjna udziałów w rynku | |
| caBTL(sym, y, x) – funkcja szacuje udziały w rynku profilów symulacyjnych na podstawie modelu probabilistycznego BTL (Bradleya-Terry’ego-Luce’a) | |
| caLogit(sym, y, x) – funkcja szacuje udziały w rynku profilów symulacyjnych na podstawie modelu logitowego | |
| caMaxUtility(sym, y, x) – funkcja szacuje udziały w rynku profilów symulacyjnych na podstawie modelu maksymalnej użyteczności | |
| Estymacja parametrów modelu conjoint analysis oraz segmentacja respondentów | |
| caModel(y, x) – funkcja szacuje parametry modelu conjoint analysis dla pojedynczego respondenta | |
| caSegmentation(y, x, c=2) – funkcja przeprowadza segmentację respondentów metodą k-średnich za pomocą funkcji kmeans() | |
| Główne wyniki conjoint analysis i analizy symulacyjnej | |
| Conjoint(y, x, z, y.type=”score”) – funkcja oblicza podstawowe wyniki conjoint analysis na poziomie zagregowanym | |
| ShowAllUtilities(y, x, z) – funkcja oblicza wszystkie dostępne w pakiecie conjoint użyteczności (cząstkowe oraz całkowite) | |
| ShowAllSimulations(sym, y, x) – funkcja szacuje udziały profilów symulacyjnych w rynku na podstawie wszystkich dostępnych w pakiecie modeli symulacyjnych | |
| Argumenty funkcji | |
| data | dane opisujące przedmiot eksperymentu (produkt, usługę) – zbiór atrybutów (czynników) oraz ich poziomów w postaci funkcji expand.grid |
| type | parametr opcjonalny określający rodzaj generowanego układu czynnikowego (domyślnie type="null" – generowany jest układ cząstkowy bez określonych kryteriów) |
| cards | parametr opcjonalny określający liczbę generowanych profilów (domyślnie cards=NA – liczba profilów wynika z rodzaju generowanego układu czynnikowego) |
| seed | parametr opcjonalny określający wartość ziarna generatora liczb pseudolosowych (domyślnie seed=123) |
| design | układ eksperymentu czynnikowego (cząstkowy lub pełny) |
| attr.names | wektor reprezentujący nazwy atrybutów (czynników) |
| lev.numbers | wektor reprezentujący liczby poziomów atrybutów (czynników) |
| prof.numbers | wektor reprezentujący numery odtwarzanych profilów |
| z | wektor reprezentujący nazwy poziomów atrybutów (czynników) |
| y.rank | macierz (wektor) preferencji empirycznych w postaci rankingowej (dane rankingowe wymagają przekształcenia na dane ratingowe za pomocą funkcji caRankToScore) |
| y | macierz (wektor) preferencji empirycznych (w postaci ocen ważności na skali ratingowej lub rankingowej) |
| x | macierz reprezentująca profile (wraz z nazwami atrybutów) |
| y.type | typ danych o preferencjach – dane w postaci ocen ważności profilów na skali ratingowej lub rankingowej (domyślnie przyjęty jest rating) |
| sym | macierz reprezentująca profile symulacyjne (wraz z nazwami atrybutów) |
| c | parametr opcjonalny określający liczbę segmentów (domyślnie c=2 – podział na 2 segmenty) |
Zbiory danych[edytuj | edytuj kod]
W wersji 1.41 pakietu znajduje się 9 zbiorów danych, które umożliwiają prezentację działania poszczególnych funkcji pakietu conjoint. W każdym ze zbiorów zawarte są przykładowe dane opisujące: preferencje respondentów (w postaci macierzy i/lub wektora danych), układ badania w postaci cząstkowego układu eksperymentu (w postaci macierzy danych) oraz nazwy poziomów poszczególnych zmiennych (w postaci wektora danych). W niektórych zbiorach danych znajduje się dodatkowo układ badania z profilami symulacyjnymi (w postaci macierzy danych), który umożliwia analizę udziału w rynku profilów (produktów lub usług), które pierwotnie nie zostały uwzględnione w cząstkowych układzie eksperymentu. Szczegółowa charakterystyka wszystkich zbiorów danych dostępna jest w oficjalnej dokumentacji[8] pakietu conjoint programu R. W tabeli zestawiono zwięzły opis zawartości wybranych zbiorów danych pakietu conjoint.
| Nazwa zbioru danych | Opis | Zawartość (w tym nazwy zmiennych) |
|---|---|---|
| ice | Przykładowe dane o preferencjach konsumentów lodów na skali rankingowej (wymagają przekształcenia na dane ratingowe). Produkt opisany 4 atrybutami (wraz z następującymi poziomami atrybutów): flavour (chocolate, vanilla, strawberry), price ($1.50, $2.00, $2.50), container (cone, cup) and topping (yes, no). | ipref – macierz preferencji (6 respondentów i 9 profilów) iprof – macierz profilów (4 atrybuty i 9 profilów), ilevn – wektor nazw poziomów atrybutów (10 poziomów). |
| tea | Dane o preferencjach konsumentów herbaty na skali ratingowej (pozycyjnej) zgromadzone w 2007 roku. Produkt opisany 4 atrybutami (wraz z następującymi poziomami atrybutów): price (low, medium, high), variety (black, green, red), kind (bags, granulated, leafy) and aroma (yes, no). | tprefm – macierz preferencji (100 respondentów i 13 profilów), tpref – wektor preferencji (długość 1300), tprof – macierz profilów (4 atrybuty i 13 profilów), tlevn – wektor nazw poziomów atrybutów (11 poziomów), tsimp – macierz profilów symulacyjnych (4 atrybuty i 4 profile). |
| chocolate | Dane o preferencjach konsumentów czekolady na skali ratingowej (pozycyjnej) zgromadzone w 2000 roku. Produkt opisany 5 atrybutami (wraz z następującymi poziomami atrybutów): kind (milk, walnut, delicaties, dark), price (low, average, high), packing (paperback, hardback), weight (light, middle, heavy) and calorie (little, much). | cprefm – macierz preferencji (87 respondentów i 16 profilów), cpref – wektor preferencji (długość 1392), cprof – macierz profilów (5 atrybutów i 16 profilów), clevn – wektor nazw poziomów atrybutów (14 poziomów), csimp – macierz profilów symulacyjnych (5 atrybutów i 4 profile). |
| journey | Dane o preferencjach konsumentów produktu turystycznego w postaci wycieczki na skali ratingowej (pozycyjnej) zgromadzone w latach 2015-2016. Produkt opisany 4 atrybutami (wraz z następującymi poziomami atrybutów): purpose (cognitive, vacation, health, business), form (organized, own), season (summer, winter) and accommodation (1-2-3 star hotel, 4-5 star hotel, guesthouse, hostel). | jpref – macierz preferencji (306 respondetów i 14 profilów), jprof – macierz profilów (4 atrybuty i 14 profilów), jlevn – wektor nazw poziomów atrybutów (12 poziomów), csimp – macierz profilów symulacyjnych (4 atrybuty i 5 profilów). |
> library(conjoint)
> data(tea)
> ls()
[1] "tlevn" "tpref" "tprefm" "tprof" "tsimp"
> print(tprof)
price variety kind aroma
1 3 1 1 1
2 1 2 1 1
3 2 2 2 1
4 2 1 3 1
5 3 3 3 1
6 2 1 1 2
7 3 2 1 2
8 2 3 1 2
9 3 1 2 2
10 1 3 2 2
11 1 1 3 2
12 2 2 3 2
13 3 2 3 2
> print(tsimp)
price variety kind aroma
1 3 2 2 2
2 1 3 1 1
3 2 3 3 2
4 3 1 2 1
> print(tlevn)
levels
1 low
2 medium
3 high
4 black
5 green
6 red
7 bags
8 granulated
9 leafy
10 yes
11 no
> tpref[1:78,]
[1] 8 1 1 3 9 2 7 2 2 2 2 3 4 0 10 3 5 1 4 8 6 2 9 7 5 2 4 10 3 5 4 1 2 0 0 1
[37] 8 9 7 6 7 4 9 6 3 7 4 8 5 2 10 9 5 1 7 8 6 10 7 10 6 6 6 10 7 10 1 1 5 1 0 0
[73] 0 0 0 0 1 1
> head(tprefm)
profil1 profil2 profil3 profil4 profil5 profil6 profil7 profil8 profil9 profil10 profil11 profil12 profil13
1 8 1 1 3 9 2 7 2 2 2 2 3 4
2 0 10 3 5 1 4 8 6 2 9 7 5 2
3 4 10 3 5 4 1 2 0 0 1 8 9 7
4 6 7 4 9 6 3 7 4 8 5 2 10 9
5 5 1 7 8 6 10 7 10 6 6 6 10 7
6 10 1 1 5 1 0 0 0 0 0 0 1 1
Praktyczne zastosowania pakietu conjoint programu R[edytuj | edytuj kod]
Przykład 1. Analiza preferencji konsumentów lodów na podstawie danych zgromadzonych na skali rang[edytuj | edytuj kod]
Konstrukcja badania[edytuj | edytuj kod]
Deklaracja zmiennych badania (wraz z odpowiadającymi im poziomami zmiennych): flavour (chocolate, vanilla, strawberry), price ($1.50, $2.00, $2.50), container (cone, cup) oraz topping (yes, no):
> library(conjoint)
> experiment<-expand.grid(
+ flavor=c("chocolate","vanilla","strawberry"),
+ price=c("$1.50","$2.00","$2.50"),
+ container=c("cone","cup"),
+ topping=c("yes","no"))
Wyznaczanie cząstkowego, ortogonalnego układu czynnikowego z zachowaniem nazw zmiennych oraz ich poziomów na potrzeby konstrukcji kwestionariusza ankietowego:
> factdesign<-caFactorialDesign(data=experiment,type="orthogonal")
> print(factdesign)
flavor price container topping
2 vanilla $1.50 cone yes
6 strawberry $2.00 cone yes
10 chocolate $1.50 cup yes
13 chocolate $2.00 cup yes
17 vanilla $2.50 cup yes
18 strawberry $2.50 cup yes
25 chocolate $2.50 cone no
30 strawberry $1.50 cup no
32 vanilla $2.00 cup no
Kodowanie poziomów zmiennych układu cząstkowego:
> prof=caEncodedDesign(design=factdesign)
> print(prof)
flavor price container topping
2 2 1 1 1
6 3 2 1 1
10 1 1 2 1
13 1 2 2 1
17 2 3 2 1
18 3 3 2 1
25 1 3 1 2
30 3 1 2 2
32 2 2 2 2
Weryfikacja (z wykorzystaniem macierzy kowariancji i korelacji) jakości układu cząstkowego:
> print(round(cov(prof),5))
flavor price container topping
flavor 0.75 0.00 0.00 0.00
price 0.00 0.75 0.00 0.00
container 0.00 0.00 0.25 0.00
topping 0.00 0.00 0.00 0.25
> print(round(cor(prof),5))
flavor price container topping
flavor 1 0 0 0
price 0 1 0 0
container 0 0 1 0
topping 0 0 0 1
> print(det(cor(prof)))
[1] 1
Wczytanie danych[edytuj | edytuj kod]
Wczytanie z plików zewnętrznych: danych o preferencjach empirycznych, układu badania, nazw zmiennych i ich poziomów:
> pref=read.csv2("ice_preferences.csv", header=TRUE)
> profiles=read.csv2("ice_profiles.csv", header=TRUE)
> levelnames=read.csv2("ice_levels.csv", header=TRUE)
> print(pref)
profile1 profile2 profile3 profile4 profile5 profile6 profile7 profile8 profile9
1 1 6 2 7 8 4 3 9 5
2 3 4 9 8 1 5 7 6 2
3 3 5 1 6 8 9 2 7 4
4 1 4 2 8 9 5 7 6 3
5 2 6 3 7 8 1 4 5 9
6 2 5 9 6 7 8 3 4 1
> print(profiles)
flavour price container topping
1 2 1 1 1
2 3 2 1 1
3 1 1 2 1
4 1 2 2 1
5 2 3 2 1
6 3 3 2 1
7 1 3 1 2
8 3 1 2 2
9 2 2 2 2
> print(levelnames)
levels
1 chocolate
2 vanilla
3 strawberry
4 $1.50
5 $2.00
6 $2.50
7 cone
8 cup
9 yes
10 no
Pliki danych w formacie .csv (rozdzielany przecinkami) do pobrania: ice_preferences.csv, ice_profiles.csv, ice_levels.csv
Zmiana formatu danych o preferencjach z porządkowania rangowego (tzw. ranking) na oceny ważności (tzw. rating):
> preferences=caRankToScore(y.rank=pref)
> print(preferences)
profile1 profile2 profile3 profile4 profile5 profile6 profile7 profile8 profile9
1 9 4 8 3 2 6 7 1 5
2 7 6 1 2 9 5 3 4 8
3 7 5 9 4 2 1 8 3 6
4 9 6 8 2 1 5 3 4 7
5 8 4 7 3 2 9 6 5 1
6 8 5 1 4 3 2 7 6 9
Pomiar preferencji na poziomie indywidualnym (dla wybranych respondentów)[edytuj | edytuj kod]
Oczacowanie modelu conjoint analysis dla 1-go respondenta:
> caModel(preferences[1,],profiles)
Call:
lm(formula = frml)
Residuals:
1 2 3 4 5 6 7 8 9
6.667e-01 -6.667e-01 1.500e+00 -1.500e+00 -2.833e+00 2.833e+00 2.591e-16 -2.167e+00 2.167e+00
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.2500 1.4633 3.588 0.0697 .
factor(x$flavour)1 1.0000 1.8509 0.540 0.6431
factor(x$flavour)2 0.3333 1.8509 0.180 0.8737
factor(x$price)1 1.0000 1.8509 0.540 0.6431
factor(x$price)2 -1.0000 1.8509 -0.540 0.6431
factor(x$container)1 1.2500 1.3882 0.900 0.4629
factor(x$topping)1 0.5000 1.3882 0.360 0.7532
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 3.926 on 2 degrees of freedom
Multiple R-squared: 0.4861, Adjusted R-squared: -1.056
F-statistic: 0.3153 on 6 and 2 DF, p-value: 0.8851
Wyznaczanie relatywnej ważności zmiennych (atrybutów) dla 1-go respondenta:
> importance=caImportance(y=preferences[1,],x=profiles)
> print(importance)
[1] 29.79 25.53 31.91 12.77
Pomiar preferencji na poziomie zagregowanym (w przekroju respondentów)[edytuj | edytuj kod]
Pomiar użyteczności cząstkowych:
> partutilities=caPartUtilities(y=preferences,x=profiles,z=levelnames)
> print(partutilities)
intercept chocolate vanilla strawberry $1.50 $2.00 $2.50 cone cup yes no
[1,] 5.250 1.000 0.333 -1.333 1.000 -1.000 0.000 1.25 -1.25 0.50 -0.50
[2,] 5.083 -3.000 3.000 0.000 -1.000 0.333 0.667 0.25 -0.25 0.00 0.00
[3,] 5.583 2.000 0.000 -2.000 1.333 0.000 -1.333 1.25 -1.25 -0.50 0.50
[4,] 5.167 -0.667 0.667 0.000 2.000 0.000 -2.000 0.75 -0.75 0.25 -0.25
[5,] 5.000 0.333 -1.333 1.000 1.667 -2.333 0.667 0.75 -0.75 0.75 -0.75
[6,] 6.000 -1.000 1.667 -0.667 0.000 1.000 -1.000 1.25 -1.25 -1.75 1.75
Pomiar użyteczności całkowitych:
> totalutilities=caTotalUtilities(y=preferences,x=profiles)
> print(totalutilities)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9]
[1,] 8.333 4.667 6.500 4.500 4.833 3.167 7 3.167 2.833
[2,] 7.333 5.667 0.833 2.167 8.500 5.500 3 3.833 8.167
[3,] 7.667 4.333 7.167 5.833 2.500 0.500 8 4.167 4.833
[4,] 8.833 6.167 6.000 4.000 3.333 2.667 3 6.167 4.833
[5,] 6.833 5.167 7.000 3.000 4.333 6.667 6 6.167 -0.167
[6,] 7.167 5.833 2.000 3.000 3.667 1.333 7 5.833 9.167
Podsumowanie najważniejszych wyników pomiaru preferencji funkcją Conjoint:
> Conjoint(y=preferences,x=profiles,z=levelnames)
Call:
lm(formula = frml)
Residuals:
Min 1Q Median 3Q Max
-3,9444 -1,6944 0,0833 1,3333 5,6944
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5,3472 0,3747 14,269 <2e-16 ***
factor(x$flavour)1 -0,2222 0,4740 -0,469 0,6414
factor(x$flavour)2 0,7222 0,4740 1,524 0,1343
factor(x$price)1 0,8333 0,4740 1,758 0,0853 .
factor(x$price)2 -0,3333 0,4740 -0,703 0,4854
factor(x$container)1 0,9167 0,3555 2,578 0,0131 *
factor(x$topping)1 -0,1250 0,3555 -0,352 0,7267
---
Signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘*’ 0,05 ‘.’ 0,1 ‘ ’ 1
Residual standard error: 2,463 on 47 degrees of freedom
Multiple R-squared: 0,2079, Adjusted R-squared: 0,1068
F-statistic: 2,057 on 6 and 47 DF, p-value: 0,07656
[1] "Part worths (utilities) of levels (model parameters for whole sample):"
levnms utls
1 intercept 5,3472
2 chocolate -0,2222
3 vanilla 0,7222
4 strawberry -0,5
5 $1.50 0,8333
6 $2.00 -0,3333
7 $2.50 -0,5
8 cone 0,9167
9 cup -0,9167
10 yes -0,125
11 no 0,125
[1] "Average importance of factors (attributes):"
[1] 35,13 31,39 20,43 13,05
[1] Sum of average importance: 100
[1] "Chart of average factors importance"
-
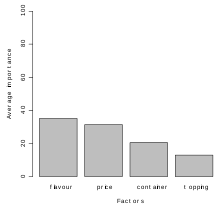 Rys. 2. Wykres ważności zmiennych (atrybutów)
Rys. 2. Wykres ważności zmiennych (atrybutów) -
 Rys. 3. Wykres preferencji poziomów zmiennej smak
Rys. 3. Wykres preferencji poziomów zmiennej smak -
 Rys. 4. Wykres preferencji poziomów zmiennej cena
Rys. 4. Wykres preferencji poziomów zmiennej cena -
 Rys. 5. Wykres preferencji poziomów zmiennej opakowanie
Rys. 5. Wykres preferencji poziomów zmiennej opakowanie -
 Rys. 6. Wykres preferencji poziomów zmiennej posypka
Rys. 6. Wykres preferencji poziomów zmiennej posypka





Przykład 2. Pomiar preferencji turystów na podstawie danych zgromadzonych w postaci ocen na skali przedziałowej[edytuj | edytuj kod]
Konstrukcja badania[edytuj | edytuj kod]
Deklaracja zmiennych badania (wraz z odpowiadającymi im poziomami zmiennych): purpose (cognitive, vacation, health, business), form (organized, own), season (summer, winter), accommodation (1-2-3 star hotel, 4-5 star hotel, guesthouse, hostel):
> library(conjoint)
> journey<-expand.grid(purpose=c("cognitive","vacation","health","business"),
+ form=c("own","organized"),
+ season=c("summer","winter"),
+ accommodation=c("1-2-3 star hotel","4-5 star hotel","guesthouse","hostel"))
Wyznaczanie cząstkowego układu czynnikowego z zachowaniem nazw zmiennych oraz ich poziomów na potrzeby konstrukcji kwestionariusza ankietowego:
> journeyfactdesign<-caFactorialDesign(data=journey,type="fractional")
> journeyfactdesign
purpose form season accommodation
1 cognitive own summer 1-2-3 star hotel
8 business organized summer 1-2-3 star hotel
10 vacation own winter 1-2-3 star hotel
15 health organized winter 1-2-3 star hotel
19 health own summer 4-5 star hotel
21 cognitive organized summer 4-5 star hotel
30 vacation organized winter 4-5 star hotel
34 vacation own summer guesthouse
39 health organized summer guesthouse
41 cognitive own winter guesthouse
48 business organized winter guesthouse
54 vacation organized summer hostel
60 business own winter hostel
61 cognitive organized winter hostel
Kodowanie poziomów zmiennych układu cząstkowego:
> prof=caEncodedDesign(design=journeyfactdesign)
> prof
purpose form season accommodation
1 1 1 1 1
8 4 2 1 1
10 2 1 2 1
15 3 2 2 1
19 3 1 1 2
21 1 2 1 2
30 2 2 2 2
34 2 1 1 3
39 3 2 1 3
41 1 1 2 3
48 4 2 2 3
54 2 2 1 4
60 4 1 2 4
61 1 2 2 4
Wczytanie danych[edytuj | edytuj kod]
Wczytanie z plików zewnętrznych: danych o preferencjach empirycznych, układu badania, nazw zmiennych i ich poziomów oraz profilów symulacyjnych:
> preferences=read.csv2("journey_preferences.csv", header=TRUE)
> profiles=read.csv2("journey_profiles.csv", header=TRUE)
> levelnames=read.csv2("journey_levels.csv", header=TRUE)
> simulations=read.csv2("journey_simulations.csv", header=TRUE)
> print(head(preferences))
profile01 profile02 profile03 profile04 profile05 profile06 profile07 profile08 profile09 profile10 profile11 profile12 profile13 profile14
1 0 10 0 10 10 8 4 5 10 2 4 0 0 6
2 10 0 10 3 7 9 2 7 4 0 8 10 3 7
3 8 2 6 9 7 9 0 1 8 5 0 0 0 5
4 8 10 1 6 3 0 3 1 8 4 7 4 1 10
5 3 4 8 10 10 1 10 4 9 4 10 0 7 10
6 5 1 8 3 10 0 9 5 3 10 10 4 1 8
> print(profiles)
purpose form season accommodation
1 1 1 1 1
2 4 2 1 1
3 2 1 2 1
4 3 2 2 1
5 3 1 1 2
6 1 2 1 2
7 2 2 2 2
8 2 1 1 3
9 3 2 1 3
10 1 1 2 3
11 4 2 2 3
12 2 2 1 4
13 4 1 2 4
14 1 2 2 4
> print(levelnames)
levels
1 cognitive
2 vacation
3 health
4 business
5 organized
6 own
7 summer
8 winter
9 1-2-3 star_hotel
10 4-5 star_hotel
11 guesthouse
12 hostel
> print(simulations)
purpose form season accommodation
1 2 2 1 1
2 2 1 1 2
3 3 2 2 2
4 1 1 1 4
5 4 1 2 3
Pliki danych w formacie .csv (rozdzielany przecinkami) do pobrania: journey_preferences.csv, journey_profiles.csv, journej_levels.csv, journey_simulations.csv
Pomiar preferencji (na poziomie indywidualnym oraz zagregowanym)[edytuj | edytuj kod]
Pomiar użyteczności cząstkowych (w przekroju respondentów):
> partutilities=caPartUtilities(y=preferences,x=profiles,z=levelnames)
> print(head(partutilities))
intercept cognitive vacation health business organized own summer winter 1-2-3 star_hotel 4-5 star_hotel guesthouse hostel
[1,] 4.938 -0.937 -2.687 3.639 -0.014 -1.562 1.562 0.692 -0.692 0.063 1.639 0.313 -2.014
[2,] 5.625 0.875 1.625 -0.827 -1.673 0.250 -0.250 1.058 -1.058 0.125 -0.452 -0.875 1.202
[3,] 4.187 2.563 -2.437 3.341 -3.466 0.063 -0.063 0.135 -0.135 2.062 -0.034 -0.688 -1.341
[4,] 4.375 1.125 -2.125 0.788 0.212 -1.625 1.625 0.346 -0.346 1.875 -2.962 0.625 0.462
[5,] 6.688 -2.187 -1.187 3.534 -0.159 -0.062 0.062 -2.385 2.385 -0.437 1.034 0.062 -0.659
[6,] 5.500 0.250 1.000 0.202 -1.452 0.750 -0.750 -1.808 1.808 -1.250 1.202 1.500 -1.452
Pomiar użyteczności całkowitych (w przekroju respondentów):
> totalutilities=caTotalUtilities(y=preferences,x=profiles)
> print(head(totalutilities))
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
[1,] 3.192 7.240 0.058 9.510 9.346 7.894 4.760 1.692 11.144 2.058 6.106 2.490 0.654 2.856
[2,] 7.933 4.885 6.567 3.615 5.654 6.856 5.490 7.683 4.731 4.817 1.769 9.260 4.346 6.394
[3,] 9.010 2.856 3.740 9.394 7.692 6.788 1.519 1.260 6.913 5.990 -0.163 0.481 -0.692 5.212
[4,] 6.096 8.433 2.154 8.317 0.923 4.510 0.567 1.596 7.760 4.154 6.490 4.683 3.077 7.240
[5,] 1.615 3.769 7.385 12.231 8.808 3.212 8.981 3.115 7.962 6.885 9.038 2.519 8.192 6.288
[6,] 3.442 0.240 7.808 5.510 5.846 4.394 8.760 6.942 4.644 9.808 6.606 2.490 5.154 5.356
Wyznaczanie relatywnej ważności cech (dla respondenta nr 306):
> importance=caImportance(y=preferences[306,],x=profiles)
> print(importance)
[1] 41.97 18.11 13.37 26.56
Podsumowanie najważniejszych wyników pomiaru preferencji poleceniem Conjoint (dla respondenta nr 306):
> Conjoint(preferences[306,],profiles,levelnames)
Call:
lm(formula = frml)
Residuals:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
2,192308 -2,009615 2,557692 -2,740385 0,346154 -0,355769 0,009615 -3,307692 2,394231 -1,442308 2,355769 0,740385 -0,346154 -0,394231
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4,9375 0,8685 5,685 0,00235 **
factor(x$purpose)1 1,3125 1,4003 0,937 0,39165
factor(x$purpose)2 -0,4375 1,4003 -0,312 0,76733
factor(x$purpose)3 1,7356 1,6158 1,074 0,33184
factor(x$form)1 0,9375 0,8685 1,080 0,32966
factor(x$season)1 -0,6923 0,8617 -0,803 0,45823
factor(x$accommodation)1 1,3125 1,4003 0,937 0,39165
factor(x$accommodation)2 0,7356 1,6158 0,455 0,66802
factor(x$accommodation)3 -1,4375 1,4003 -1,027 0,35171
---
Signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘*’ 0,05 ‘.’ 0,1 ‘ ’ 1
Residual standard error: 3,107 on 5 degrees of freedom
Multiple R-squared: 0,6034, Adjusted R-squared: -0,0311
F-statistic: 0,951 on 8 and 5 DF, p-value: 0,549
[1] "Part worths (utilities) of levels (model parameters for whole sample):"
levnms utls
1 intercept 4,9375
2 cognitive 1,3125
3 vacation -0,4375
4 health 1,7356
5 business -2,6106
6 organized 0,9375
7 own -0,9375
8 summer -0,6923
9 winter 0,6923
10 1-2-3 star_hotel 1,3125
11 4-5 star_hotel 0,7356
12 guesthouse -1,4375
13 hostel -0,6106
[1] "Average importance of factors (attributes):"
[1] 41,97 18,11 13,37 26,56
[1] Sum of average importance: 100,01
[1] "Chart of average factors importance"
Podsumowanie najważniejszych wyników pomiaru preferencji poleceniem Conjoint (w przekroju respondentów):
> Conjoint(y=preferences,x=profiles,z=levelnames)
Call:
lm(formula = frml)
Residuals:
Min 1Q Median 3Q Max
-5,4460 -3,0144 -0,0949 2,7758 5,9051
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4,979371 0,052578 94,704 < 2e-16 ***
factor(x$purpose)1 0,139093 0,084780 1,641 0,1009
factor(x$purpose)2 0,146446 0,084780 1,727 0,0842 .
factor(x$purpose)3 0,437924 0,097823 4,477 7,78e-06 ***
factor(x$form)1 -0,070057 0,052578 -1,332 0,1828
factor(x$season)1 -0,094834 0,052172 -1,818 0,0692 .
factor(x$accommodation)1 -0,136234 0,084780 -1,607 0,1081
factor(x$accommodation)2 -0,028171 0,097823 -0,288 0,7734
factor(x$accommodation)3 0,005923 0,084780 0,070 0,9443
---
Signif. codes: 0 ‘***’ 0,001 ‘**’ 0,01 ‘*’ 0,05 ‘.’ 0,1 ‘ ’ 1
Residual standard error: 3,291 on 4275 degrees of freedom
Multiple R-squared: 0,01474, Adjusted R-squared: 0,0129
F-statistic: 7,994 on 8 and 4275 DF, p-value: 9,444e-11
[1] "Part worths (utilities) of levels (model parameters for whole sample):"
levnms utls
1 intercept 4,9794
2 cognitive 0,1391
3 vacation 0,1464
4 health 0,4379
5 business -0,7235
6 organized -0,0701
7 own 0,0701
8 summer -0,0948
9 winter 0,0948
10 1-2-3 star_hotel -0,1362
11 4-5 star_hotel -0,0282
12 guesthouse 0,0059
13 hostel 0,1585
[1] "Average importance of factors (attributes):"
[1] 38,62 13,30 13,97 34,11
[1] Sum of average importance: 100
[1] "Chart of average factors importance"
-
 Rys. 7. Wykres ważności zmiennych (atrybutów)
Rys. 7. Wykres ważności zmiennych (atrybutów) -
 Rys. 8. Wykres preferencji poziomów zmiennej cel
Rys. 8. Wykres preferencji poziomów zmiennej cel -
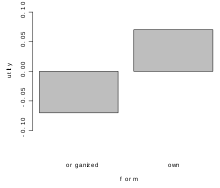 Rys. 9. Wykres preferencji poziomów zmiennej forma
Rys. 9. Wykres preferencji poziomów zmiennej forma -
 Rys. 10. Wykres preferencji poziomów zmiennej sezon
Rys. 10. Wykres preferencji poziomów zmiennej sezon -
 Rys. 11. Wykres preferencji poziomów zmiennej zakwaterowanie
Rys. 11. Wykres preferencji poziomów zmiennej zakwaterowanie





Segmentacja respondentów[edytuj | edytuj kod]
Segmentacja metodą k-średnich – domyślny podział na 2 segmenty:
> segments<-caSegmentation(preferences,profiles)
> print(segments$seg)
K-means clustering with 2 clusters of sizes 149, 157
Cluster means:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
1 6.025658 3.686060 5.200852 5.08743 4.808973 5.088503 4.263604 4.948477 4.835148 6.630383 4.290691 3.291765 3.721228 4.973577
2 3.670554 4.482898 4.837408 5.78621 5.618357 5.043720 6.210573 4.984248 5.933051 3.743459 4.555803 7.127006 5.120497 5.886217
Clustering vector:
[1] 2 2 1 1 2 1 1 1 2 1 2 1 2 1 1 2 1 1 1 2 1 1 2 1 2 2 1 2 1 2 1 2 1 1 1 1 2 1 1 1 1 1 2 2 2 1 1 2 2 1 2 1 1 1 1 1 1 2 2 1 2 1 1 2 2 1 1 2 2 1 1 2 1
[74] 1 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 1 2 2 2 2 1 2 1 2 2 2 2 1 1 2 2 2 2 1 2 2 2 2 2 1 1 2 2 1 2 2 1 1 1 2 2 1 1 2 1 1 2 1 1 2 2 2 1 1 1 2 1 2 2 1 2 2
[147] 2 2 2 2 2 2 1 2 2 1 1 1 2 1 2 2 2 1 2 2 2 2 1 2 1 2 1 2 2 1 2 1 2 2 2 2 2 1 2 2 2 2 2 2 2 2 1 1 2 1 1 1 2 1 1 2 1 2 2 1 2 2 2 2 2 1 1 1 2 1 1 2 1
[220] 1 2 2 2 2 2 2 1 2 1 1 2 1 1 1 2 2 2 1 1 1 2 1 1 1 2 2 1 1 1 1 2 2 2 1 1 2 2 1 2 1 2 1 2 1 1 2 1 1 1 1 1 2 2 1 1 1 2 2 2 1 2 1 1 1 1 2 1 1 1 2 1 1
[293] 2 1 1 1 1 2 2 1 1 2 1 1 1 1
Within cluster sum of squares by cluster:
[1] 12885.85 11758.15
(between_SS / total_SS = 10.6%)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" "size" "iter" "ifault"
Segmentacja metodą k-średnich – podział na 3 segmenty:
> segments<-caSegmentation(preferences,profiles,c=3)
> print(segments$seg)
K-means clustering with 3 clusters of sizes 104, 97, 105
Cluster means:
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
1 5.263000 3.860952 4.155269 7.124625 7.068404 4.630298 3.522462 3.895212 6.864673 5.561519 4.159365 3.494365 4.614288 5.160567
2 5.602402 3.695979 6.044505 3.409691 3.393330 5.303907 5.746031 6.161680 3.526845 6.583165 4.676763 4.284897 3.513887 4.706402
3 3.650619 4.695133 4.913667 5.664390 5.089067 5.276390 6.539390 4.924429 5.675200 3.416048 4.460514 7.908229 5.120457 6.399800
Clustering vector:
[1] 1 3 1 1 1 2 2 2 2 1 3 1 1 2 2 3 1 1 2 1 1 2 1 2 3 3 2 2 1 3 2 3 2 2 2 2 3 2 1 2 2 1 2 3 3 2 2 3 3 1 3 2 2 1 2 2 1 3 1 2 3 1 2 3 2 1 1 3 1 2 2 1 2
[74] 2 1 1 1 1 3 3 3 3 3 3 3 1 3 2 2 1 3 3 3 3 1 3 2 3 3 3 3 2 2 3 3 2 3 1 3 3 3 1 2 2 2 3 3 2 3 3 2 1 2 3 3 2 2 1 1 1 3 1 1 3 1 1 2 3 2 3 2 3 3 1 3 1
[147] 1 1 3 3 1 3 2 2 1 2 1 2 3 1 3 3 1 2 1 3 3 3 1 3 2 3 1 3 3 1 3 2 2 1 3 1 3 2 3 3 3 3 2 3 3 3 2 1 3 2 2 2 1 1 1 3 1 3 3 1 2 3 3 1 2 1 1 2 3 2 2 3 1
[220] 2 3 3 3 3 3 2 2 2 2 1 2 2 2 1 1 1 3 2 1 1 3 1 1 2 3 3 1 2 1 1 1 1 1 1 2 3 1 1 3 2 2 1 1 1 1 1 2 2 1 2 1 3 3 1 1 1 3 1 3 2 3 2 1 2 1 3 2 1 1 1 2 2
[293] 3 2 1 2 2 3 3 2 1 3 1 2 1 1
Within cluster sum of squares by cluster:
[1] 8321.434 7030.496 7021.380
(between_SS / total_SS = 18.9%)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" "size" "iter" "ifault"
Wizualizacja podziału na 3 segmenty:
> summary(segments)
Length Class Mode
segm 9 kmeans list
util 4284 -none- numeric
sclu 306 -none- numeric
> require(fpc)
> plotcluster(segments$util,segments$sclu)
> require(fpc)
> require(broom)
> require(ggplot2)
> dcf<-discrcoord(segments$util,segments$sclu)
> assignments<-augment(segments$segm,dcf$proj[,1:2])
> ggplot(assignments)+geom_point(aes(x=X1,y=X2,color= .cluster))+labs(color="Cluster Assignment",title="K-Means Clustering Results")
-
![Rys. 9. Podział na 3 segmenty (za pomocą funkcji plotcluster pakietu fpc [Hennig 2018[13]])](//upload.wikimedia.org/wikipedia/commons/thumb/7/74/Trip_ce2_3clusters.svg/220px-Trip_ce2_3clusters.svg.png) Rys. 9. Podział na 3 segmenty (za pomocą funkcji plotcluster pakietu fpc [Hennig 2018[13]])
Rys. 9. Podział na 3 segmenty (za pomocą funkcji plotcluster pakietu fpc [Hennig 2018[13]]) -
![Rys. 10. Podział na 3 segmenty (za pomocą funkcji ggplot pakietu ggplot2 [Wickham i in. 2018[7]])](//upload.wikimedia.org/wikipedia/commons/thumb/d/d7/Trip_ce3_3clusters.svg/220px-Trip_ce3_3clusters.svg.png) Rys. 10. Podział na 3 segmenty (za pomocą funkcji ggplot pakietu ggplot2 [Wickham i in. 2018[7]])
Rys. 10. Podział na 3 segmenty (za pomocą funkcji ggplot pakietu ggplot2 [Wickham i in. 2018[7]])
![Rys. 9. Podział na 3 segmenty (za pomocą funkcji plotcluster pakietu fpc [Hennig 2018[13]])](/wiki/Plik:Trip_ce2_3clusters.svg)
![Rys. 10. Podział na 3 segmenty (za pomocą funkcji ggplot pakietu ggplot2 [Wickham i in. 2018[7]])](/wiki/Plik:Trip_ce3_3clusters.svg)
Analiza udziału w rynku profilów symulacyjnych[edytuj | edytuj kod]
Analiza udziału w rynku profilów symulacyjnych za pomocą modelu maksymalnej użyteczności, modelu probabilistycznego BTL (Bradleya-Terry’ego-Luce’a) oraz modelu logitowego:
> ShowAllSimulations(sym=simulations,y=preferences,x=profiles)
TotalUtility MaxUtility BTLmodel LogitModel
1 4,96 20,26 19,31 17,51
2 4,93 11,44 20,01 15,72
3 5,55 31,05 22,32 29,02
4 5,11 24,84 20,77 23,07
5 4,29 12,42 17,59 14,68
Przypisy[edytuj | edytuj kod]
- ↑ a b Andrzej Bąk, Tomasz Bartłomowicz, conjoint: An Implementation of Conjoint Analysis Method [online], 26 lipca 2018 [dostęp 2018-07-26].
- ↑ Andrzej Bąk, Tomasz Bartłomowicz: Conjoint analysis method and its implementation in conjoint R package. W: Józef Pociecha, Reinhold Decker: Data analysis methods and its applications. Warszawa: C.H.Beck, 2012, s. 239-248. ISBN 978-83-255-3458-5. (ang.).
- ↑ Eugeniusz Gatnar, Marek Walesiak: Statystyczna analiza danych z wykorzystaniem programu R. Warszawa: Wydawnictwo Naukowe PWN, 2009. ISBN 978-83-01-15661-9. (pol.).
- ↑ R Core Team, stats: The R Stats Package [online], 8 lipca 2018 [dostęp 2018-07-07].
- ↑ a b Bob Wheeler, AlgDesign: Algorithmic Experimental Design [online], 15 października 2014 [dostęp 2018-06-30].
- ↑ Guangchuang Yu, dlstats: Download Stats of R Packages [online], 7 sierpnia 2017 [dostęp 2018-07-07].
- ↑ a b Hadley Wickham i inni, ggplot2: Create Elegant Data Visualisations Using the Grammar of Graphics [online], 3 lipca 2018 [dostęp 2018-07-07].
- ↑ a b Andrzej Bąk, Tomasz Bartłomowicz, Package 'conjoint' – manual [online], 26 lipca 2018 [dostęp 2018-07-26].
- ↑ Jinsuh Lee, Conjoint Analysis on R [online], 5 listopada 2016 [dostęp 2018-07-07].
- ↑ Markus Burkhardt, R-Stutorials – 24 Conjoint-Analyse [online], 28 stycznia 2018 [dostęp 2018-07-07].
- ↑ Martin Müller, Market Research Using Conjoint Analysis In R [online], kwiecień 2018 [dostęp 2018-07-07].
- ↑ Holly Jones, Conjoint Analysis & Segmentation [online], 2015 [dostęp 2018-07-07].
- ↑ Christian Hennig, fpc: Flexible Procedures for Clustering [online], 13 stycznia 2018 [dostęp 2018-07-07].