
Badania eksploracyjne

Badania eksploracyjne (EDA, ang. exploratory data analysis) – podejście we wnioskowaniu statystycznym obejmujące opis, wizualizację i badanie zebranych danych bez potrzeby zakładania z góry hipotez badawczych. Jest wstępnym etapem procesu naukowego. Może korzystać z metod modelowania statystycznego i weryfikacji hipotez statystycznych, ale używa ich do odnajdywania, a nie potwierdzania idei[1]. Ma ona na celu wzbogacenia wiedzy naukowej o hipotezy, które mogą nasunąć nieukierunkowana obserwacja i analizy. Badania eksploracyjne obejmują też wstępne sprawdzanie danych w celu skontrolowania założeń modeli statystycznych, lub występowania błędów w danych (np. brakujących odpowiedzi). Jest to klasyczne podejście, z którego wraz z rosnącą dostępnością komputerów wyłoniła się dziedzina komputerowej eksploracji danych (data miningu), oraz data science i big data. Eksplorację danych jako osobne podejście spopularyzował statystyk John Tukey.
Przegląd[edytuj | edytuj kod]
Tukey zdefiniował analizę danych w 1961 r. jako „procedury analizowania danych, metody interpretowania wyników takich procedur, sposoby projektowania zbierania danych w celu uczynienia ich analizy łatwiejszą lub bardziej dokładną, oraz wszystkie techniki statystyczne które mogą być stosowane w badaniu danych[2].”
Promocja podejścia EDA była jednym z czynników stojących za dynamicznym rozwojem komputerowych pakietów statystycznych, w szczególności języka S w Laboratoriach Bella, który stał się protoplastą współczesnego języka programowania statystycznego R. Ta rodzina komputerowych środowisk statystycznych rozpowszechniła nowoczesne metody wizualizacji danych, co umożliwiło statystykom sprawniejsze rozpoznawanie w danych obserwacji odstających, oraz nieprzewidzianych trendów i wzorców, które mogą być warte dalszego zbadania.
Rozwój technik eksploracyjnych był też związany z postępem w dwóch innych obszarach statystyki: metod odpornościowych oraz statystyk nieparametrycznych, które służą uniezależnieniu wnioskowania statystycznego od wyidealizowanych modeli, i zmniejszeniu jej wrażliwości na niestandardowe postaci danych. Tukey zachęcał do korzystania z większej liczby statystyk opisowych, niż tylko średniej i odchylenia standardowego, do przedstawiania zbiorów obserwacji: minimum i maksimum, mediany i kwartyli – ponieważ charakteryzują one każdy rozkład empiryczny, i są bardziej odporne wobec wysokiej skośności lub kurtozy. Komputerowe pakiety statystyczne udostępniły także metody samowsporne (bootstrap), które są nieparametryczne i szczególnie odporne dla wielu klas problemów.
Eksploracja danych, statystyki odpornościowe i nieparametryczne, oraz rozwój języków programowania statystycznego ułatwiły pracę statystyków w wielu obszarach nauki i inżynierii, i doprowadziły do wyłonienia się odrębnych dziedzin komputerowej eksploracji danych (data mining), data science i analizowaniu big data[3].
Rozwój[edytuj | edytuj kod]
John Tukey wyraził w opublikowanej w 1977 r. książce Exploratory Data Analysis przekonanie, że statystyka klasyczna kładzie zbyt duży nacisk na weryfikację hipotez statystycznych (badania konfirmacyjne); więcej uwagi należy, jego zdaniem, poświęcić możliwości używania danych na własnych prawach jako źródła nowych hipotez. Zauważył, że w praktyce badania o charakterze de facto eksploracyjnym są często przedstawiane, np. wskutek presji publikacyjnej, jako badania konfirmacyjne, co może prowadzić do systematycznych przekłamań wiążących się w podejściu częstościowym z testowaniem niezaplanowanych hipotez[4].
Cele badań eksploracyjnych obejmują:
- Proponowanie nowych hipotez o obserwowanych w danych zależnościach
- Sprawdzanie zgodności danych z założeniami modeli statystycznych
- Wybranie adekwatnego do charakteru danych zestawu narzędzi i technik analizy
Narzędzia[edytuj | edytuj kod]
Badania eksploracyjne mogą korzystać z dowolnych narzędzi, ponieważ istotą tego podejścia jest stosunek do danych i hipotez[5]. Niektóre techniki eksploracyjne to na przykład:
Wizualizacja[edytuj | edytuj kod]
Wyszukiwanie wzorców[edytuj | edytuj kod]
- Testy korelacji
- Analiza czynnikowa
- Analiza głównych składowych (PCA)
- Skalowanie wielowymiarowe
- Redukcja wymiarowości
Przykład[edytuj | edytuj kod]
Odkrycia płynące z eksploracji danych są często efektem ubocznym podstawowego badania konfirmacyjnego. Przykładem może być badanie hipotezy, że liczba osób przy stoliku restauracyjnym wpływa na wielkość otrzymanego przez obsługę napiwku[6]. Poza tymi zmiennymi, dane z badania zawierają ogólną wysokość rachunku, płeć klientów, obecność osób palących papierosy, porę dnia oraz dzień tygodnia. Test głównej hipotezy wykonany jest przy pomocy analizy regresji, która wyłania model:
napiwek = 0.18 - 0.01×liczba_osób
który sugeruje, że wysokość napiwku statystycznie maleje o 1% wraz z każdą kolejną osobą przy stoliku. Wykreślenie danych ujawnia dodatkowe potencjalne zależności, których nie przewidziano w badaniu, i które podsuwają nowe hipotezy do zbadania:
-
 Histogram wielkości napiwków, w przedziałach wartości odpowiadających wzrostowi o $1. Rozkład wartości jest prawoskośny i unimodalny, co oznacza że napiwki są w większości niewielkie.
Histogram wielkości napiwków, w przedziałach wartości odpowiadających wzrostowi o $1. Rozkład wartości jest prawoskośny i unimodalny, co oznacza że napiwki są w większości niewielkie. -
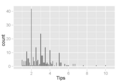 Histogram napiwków w przedziałach o szerokości odpowiadających wzrostowi o 10¢. Można zauważyć piki odpowiadające okrągłym liczbom, co wskazuje, że klienci mają skłonność do zaokrąglania kwot. Jest to często obserwowane i zrozumiałe zjawisko.
Histogram napiwków w przedziałach o szerokości odpowiadających wzrostowi o 10¢. Można zauważyć piki odpowiadające okrągłym liczbom, co wskazuje, że klienci mają skłonność do zaokrąglania kwot. Jest to często obserwowane i zrozumiałe zjawisko. -
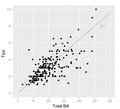 Wykres punktowy przedstawiający współzależność wysokości napiwków i płatności. Można byłoby oczekiwać bardziej ścisłej, liniowej zależności, jednak obserwujemy dużą zmienność.
Wykres punktowy przedstawiający współzależność wysokości napiwków i płatności. Można byłoby oczekiwać bardziej ścisłej, liniowej zależności, jednak obserwujemy dużą zmienność. -
 Wykres punktowy wysokości napiwków względem rachunku, podzielony według płci i obecności palaczy. Palące osoby charakteryzuje większa zmienność wysokości napiwków. Mężczyźni płacą wyższe rachunki, a niepalące kobiety są grupą najbardziej przewidywalnie dającą napiwki.
Wykres punktowy wysokości napiwków względem rachunku, podzielony według płci i obecności palaczy. Palące osoby charakteryzuje większa zmienność wysokości napiwków. Mężczyźni płacą wyższe rachunki, a niepalące kobiety są grupą najbardziej przewidywalnie dającą napiwki.




Przypisy[edytuj | edytuj kod]
- ↑ Open Science Collaboration, Maximizing the reproducibility of your research, [w:] Scott Owen Lilienfeld, Irwin Douglas Waldman (red.), Psychological Science Under Scrutiny: Recent Challenges and Proposed Solutions, New York: Wiley-Blackwell, marzec 2017, ISBN 978-1-118-66107-9.
- ↑ John Wilder Tukey, The Future of Data Analysis, „The Annals of Mathematical Statistics”, 33 (1), 1962, s. 1–67, DOI: 10.1214/aoms/1177704711, ISSN 0003-4851 [dostęp 2019-07-01] (ang.).
- ↑ Luisa T. Fernholz, Stephan Morgenthaler. A conversation with John W. Tukey and Elizabeth Tukey. „Statistical Science”. 15 (1), s. 79–94, 2000-02-01. DOI: 10.1214/ss/1009212675. ISSN 0883-4237. [dostęp 2017-01-15].
- ↑ John Wilder Tukey: Exploratory data analysis. Pearson, 1977-01-01. ISBN 978-0-201-07616-5.
- ↑ John Wilder Tukey. We Need Both Exploratory and Confirmatory. „The American Statistician”. 34 (1), s. 23–25, 1980-02-01. DOI: 10.1080/00031305.1980.10482706. ISSN 0003-1305. [dostęp 2017-01-15].
- ↑ Deborah F. Swayne, Interactive and Dynamic Graphics for Data Analysis: with R and GGobi, Springer Verlag, 2007, ISBN 978-0-387-71761-6, OCLC 154711874.